728x90
from langchain_core.prompts import (
ChatPromptTemplate,
SystemMessagePromptTemplate,
HumanMessagePromptTemplate,
AIMessagePromptTemplate,
ErrorMessagePromptTemplate,
WarningMessagePromptTemplate,
InformativeMessagePromptTemplate
)
chat_prompt = ChatPromptTemplate.from_messages(
[
# 시스템 메시지: 시스템의 기능이나 상태를 설명
SystemMessagePromptTemplate.from_template("이 시스템은 천문학 질문에 답변할 수 있습니다."),
# 사용자 메시지: 사용자가 입력한 질문이나 요청
HumanMessagePromptTemplate.from_template("{user_input}"),
# AI 응답 메시지: 고정된 응답을 지정
AIMessagePromptTemplate.from_template("태양계에서 가장 큰 행성은 목성입니다."),
# 오류 메시지: 시스템 오류가 발생했을 때
ErrorMessagePromptTemplate.from_template("오류가 발생했습니다. 다시 시도해 주세요."),
# 경고 메시지: 잘못된 입력이나 경고를 표시
WarningMessagePromptTemplate.from_template("경고: 잘못된 입력입니다."),
# 정보 메시지: 사용자가 알아야 할 추가 정보 제공
InformativeMessagePromptTemplate.from_template("추가 정보: 천문학과 관련된 최신 연구 결과는 다음 사이트를 참고하세요."),
]
)
messages = chat_prompt.format_messages(user_input="태양계에서 가장 큰 행성은 무엇인가요?")
print(messages)728x90
'AI > Data Science' 카테고리의 다른 글
| Symbols on prompt engineering (0) | 2024.07.26 |
|---|---|
| 프롬프팅 스킬 (0) | 2024.07.22 |
| LLM 프롬프트 엔지니어링, CoT (0) | 2024.07.10 |
| hugging face / Qwen2 snippent code (0) | 2024.06.17 |
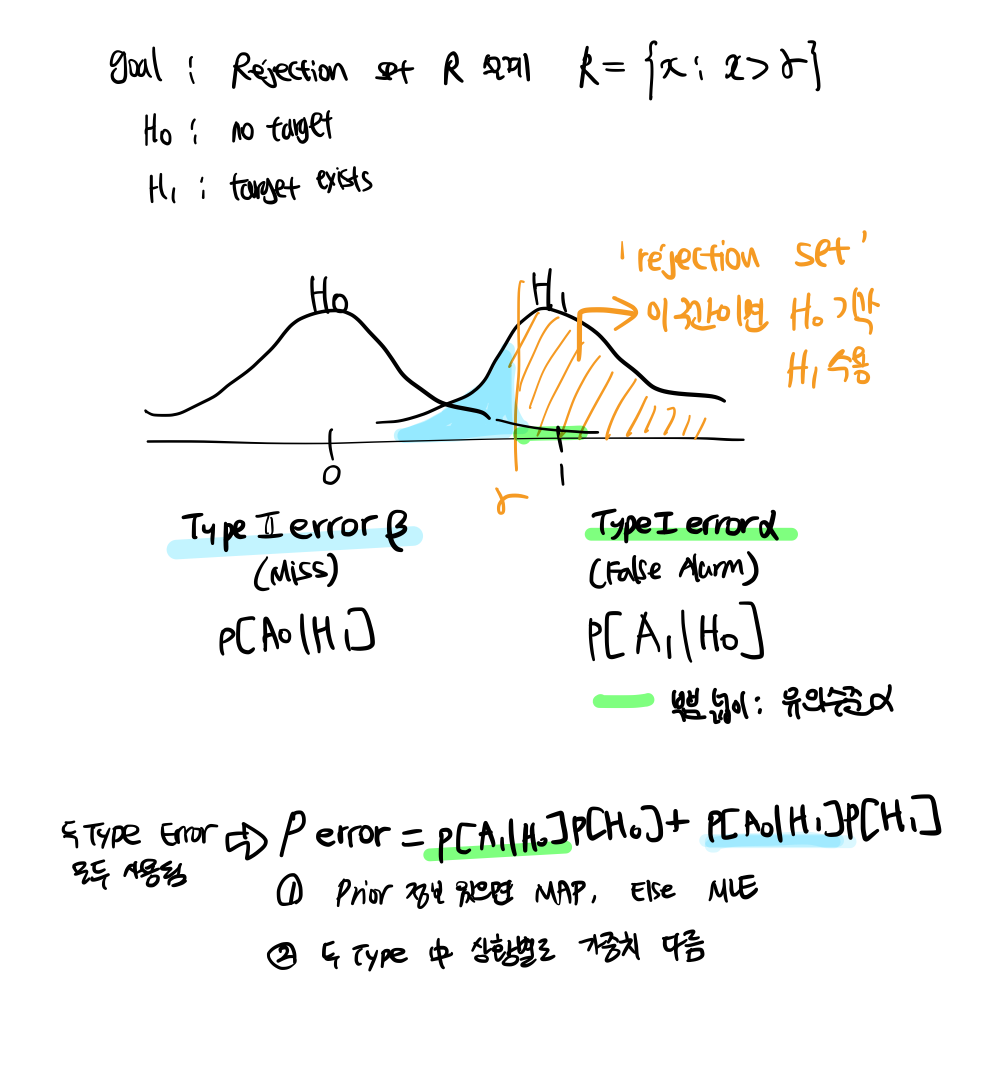
| 가설검증 Hypothesis Testing (귀무가설 / 유의수준 / p값 / 제1종의 오류, 제2종의 오류) (0) | 2024.06.03 |