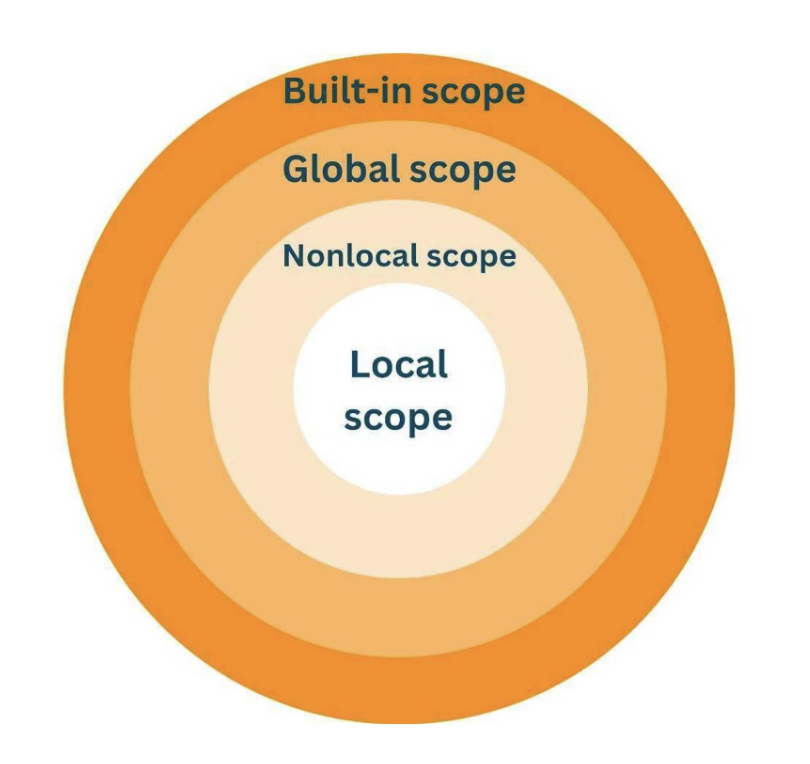
Global variable: 실행하는 파이썬 파일 전체 영역에서 사용 가능한 변수
Local variable: 특정 지역 범위에서만 영향을 주고 받을 수 있는 변수
(ex. 특정 함수 내에서 선언한 변수는 return되지 않는 한 함수 밖에서 사용될 수 없다)
#1
a = 1 #Global
def function():
print(a)
# 함수 내에서 별도 변수를 선언하지 않았으므로, Global과 구분되는 Local이 없음
# 함수 전체에 적용되는 Global 'a'가 적용됨
funtion()
print(a)
>> 1 \n 1
여기서 a는 Global variable이다.
함수 내에서 별도 변수를 선언하지 않았으므로 Local variable은 없다.
함수에서 별도로 변수를 선언하지 않으면 a는 global variable이다.
#2
def function():
a = 1
print(a)
function()
print(a)
>> 1 \n error여기서 Global variable은 없다.
함수 내에서만 변수를 선언했으므로 이것은 Local variable, 밖에서 가지고 오면 error 발생.
#3
a = 1 #Global
def function():
a = 2 #Local
print(a) #Local
function() #Local
print(a) #Global
>> 2 \n 1Python
global vs nonlocal
global
Global variable: 실행하는 파이썬 파일 전체 영역에서 사용 가능한 변수
함수 내에서 선언한 variable은 기본적으로 해당 함수에서만 사용 가능한 Local이지만, Local을 Global로 전환하는 역할.
때문에 함수 밖에서 선언된 건 global 쓸 필요 없음 (이미 Global인 상태)
#1
a = 1
def function():
global a #함수 안에서 Local이 아닌 Global을 사용하기로 선언한다
a = 2 #Global variable 'a'가 2가 된다
print(a)
function() #Global
print(a) #Global
>> 2 \n 2이때 global 선언문과 & a에 대한 식을 별도로 지정해야 한다.
| correct | error |
| global a a = 2 |
global a = 2 |
#2
def function():
global a #Local -> Global
a = 10 #Global
print(a) #Global
function() #Global
print(a) #Global
>> 10 \n 10함수 밖에서 변수를 이미 선언하지 않더라도, 함수에서 처음 생성한 변수를 Global variable로 지정할 수 있다.
nonlocal
주로 함수 def 내의 또 다른 함수 def에서 사용됨
nonlocal: lower scope에서의 local variable을 upper scope에서의 local variable로 전환하는 역할
아래 예시에서, function2에서 선언한 a는 기본적으로 function2에서만 사용 가능한 local인데,
그것의 상위 함수인 function1에서 선언한 local으로 전환(연결)하겠다는 의미.
def function():
a = 1 # function1의 Local
def function2():
nonlocal a
a = 2
# nonlocal: function2의 Local -> function1의 Local
# function1의 a를 사용하겠어 (연결되겠어)
# upper scope에서의 variable에 access
# != Global (whole scope)
function2()
print(a)
>> 2끝~
[Python] 전역 변수 지역 변수 사용법 총 정리/ global, nonlocal
Python, Global variable = 파이썬 전역 변수란 ? - Global scope, 전역 범위에서 활동하는 변수. 전역 범위란 함수를 포함하여 스크립트 전체에서 모든 요소에 해당 변수에 접근할 수 있도록 하는 것이 전역
codingpractices.tistory.com
⬆️ 위 페이지에 잘 정리되어 있음 !!!
'개발 > CS study' 카테고리의 다른 글
| [Python] 클래스 개념 정복 (0) | 2023.07.02 |
|---|---|
| [백준] 병합 정렬, 재귀, 1517 버블소트 (0) | 2023.06.29 |
| [Error] unbound variable error - python (0) | 2023.06.29 |
| [알고리즘] 정렬 / Sorting / 삽입 정렬(Insertion Sorting) (0) | 2023.06.24 |
| [백준] 구간 합 / 구간 합 구하기 5 (0) | 2023.06.24 |