로지스틱 회귀의 설명변수(독립변수) Factor의
Level이 여러 개인 (다항변수) 경우
해당 Factor를 실제 모델에 넣을 수 있게 하려면, 어떻게 represent 할 것인가?
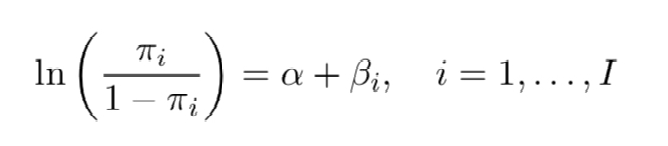
For a factor with I levels, there are I - 1 non-redundant parameters.
We can arbitrarily set any one of them to 0.
• R default is to order the levels alphabetically and set B1 = 0.
• When B1 = 0, a is the log odds at level 1.
• a + Bi is the log odds at level i, i = 2,..., I
• Bi is the log odds ratio between level i and level 1.
• Bj - Bi is the log odds ratio between levels j and i (i # j)ANOVA-Type Representation
ANOVA-type representation은 하나의 기준 수준(reference level)을 정하고, 나머지 수준(level)들을 이 기준 수준과의 차이(즉, 로그 오즈 비)로 나타냄
햄버거 가게에 세 가지 메뉴(A, B, C)가 있다고 가정할 때, A를 기준 수준으로 설정함

이때, β_B는 B 메뉴가 기준(A)보다 얼마나 더 인기 있는지, β_C는 C 메뉴가 기준(A)보다 얼마나 더 인기 있는지 나타냄
이 방법은 기준 수준과 나머지 수준 간의 차이를 표현하며, I개의 수준이 있다면 I - 1개의 파라미터를 사용함
파라미터 수를 줄이고, 수준 간 차이를 해석하기 용이한 방식임
Dummy Variable Representation
Dummy variable representation은 각 수준(level)에 대해 이진 변수(0 또는 1)를 사용하여 표현함
햄버거 가게의 A, B, C 메뉴에 대해 각각의 dummy 변수는 다음과 같이 설정됨

로지스틱 회귀 모델에서의 표현은 다음과 같음

기준 수준(A)의 γ_A는 0으로 설정되며, B와 C 수준의 효과는 각각 γ_B, γ_C로 나타남
Dummy variable representation은 모든 수준을 독립적으로 표현하고, 각 수준의 존재 여부를 명확히 나타냄
ANOVA-Type vs Dummy Variable Representation
| 기준 수준 | 기준 수준과의 차이로 표현함 | 기준 수준도 포함하여 모두 독립적으로 표현함 |
| 파라미터 수 | I - 1개의 파라미터를 사용함 | I - 1개의 dummy 변수를 사용함 |
| 표현 방식 | 상대적으로 수준 간 차이를 표현함 | 절대적으로 각 수준을 개별적으로 표현함 |
| 해석 용이성 | 수준 간의 차이를 직관적으로 해석하기 쉬움 | 각 수준의 효과를 명확히 확인 가능함 |
| 복잡성 | 중복을 제거하여 상대적으로 단순함 | 조금 더 파라미터가 많아 상대적으로 복잡함 |
예시: 어떤 햄버거가 가장 인기 있는가?
ANOVA-Type Representation
기준 수준: 메뉴 A
B의 로그 오즈가 +1.5, C의 로그 오즈가 −0.5라면,
- B는 A보다 인기가 많음
- C는 A보다 인기가 적음
Dummy Variable Representation

결론
해석이 중요한 경우 ANOVA-Type이 기준과의 차이를 직관적으로 보여줘서 유리함
수준 간 독립적 효과가 필요한 경우 Dummy Variable Representation이 적합함
상황에 따라 두 방법 중 하나를 선택하여 활용해야 함
'AI > Data Science' 카테고리의 다른 글
| [Statistics] Polynomial Logit Model - 팩터에 거듭제곱이 붙는다 (0) | 2024.12.15 |
|---|---|
| [Statistics] Dummy Variable Representation 예시 - 행렬곱 (0) | 2024.12.14 |
| [Statistics] 정규분포 근사...의 모든 것. (0) | 2024.10.19 |
| [Statistics] 기초통계학 정리 (0) | 2024.10.02 |
| 삼각 함수 공식 (1) | 2024.09.20 |