중심 극한 정리(CLT, Central Limit Theorem)
데이터 사이언스, 추천 시스템, Data Science, Recommender
gguguk.github.io

핵심은,
iid인 동일 모집단에서 추출된 표본들의 합(X1+X2+....Xn) 혹은 표본평균((X1+X2+....Xn)/n)이
→ 모집단 분포와 관계없이 정규분포에 수렴한다
따라서,
가 성립하게 된다.
잠깐.. 기초 공식
#1
#2
#3
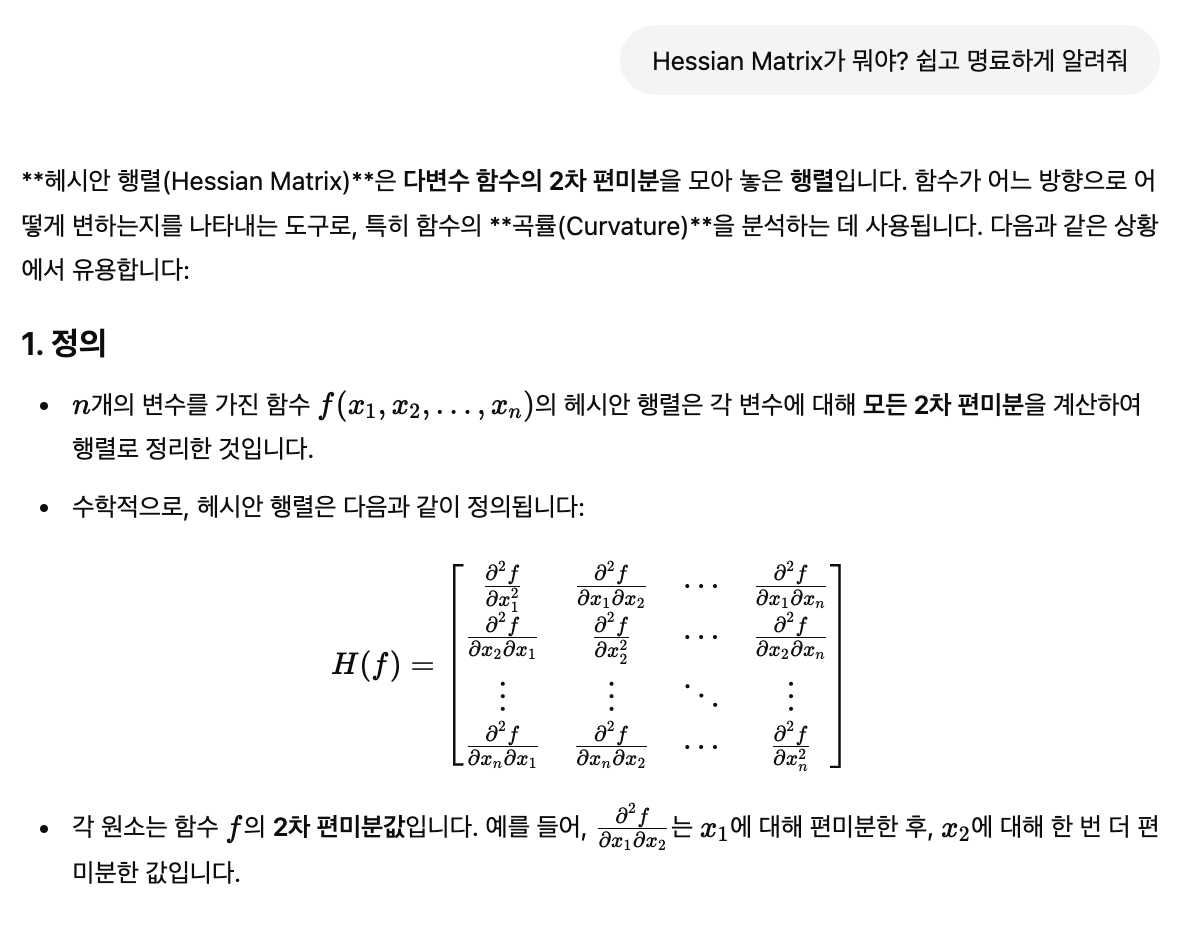
대상이 벡터인 경우, 벡터의 분산은 -> 공분산 행렬 형태로 나타남
https://blog.naver.com/PostView.naver?blogId=waterforall&logNo=222789143718
[생존수학] 공분산(covariance) 및 공분산 행렬(covariance matrix), 공분산과 상관계수(correlation coefficient)
이 글을 읽기 전에, 기댓값(expected value)과 분산(variance)에 대해서 알고 있다고 가정합니다. 혹시, 그...
blog.naver.com
#적용 (1)


#1
#적용 (2)

# 정리 (1)
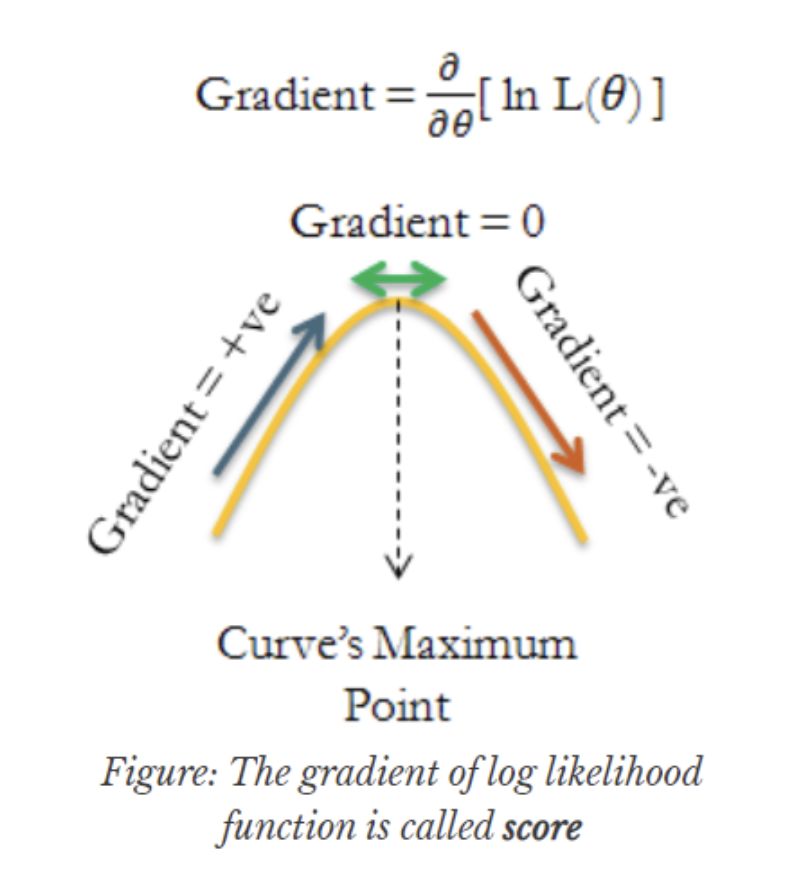
1) Fisher information은 score function의 분산.
- 만약 score function이 벡터라면 Fisher information은 공분산 행렬이 됩니다.
2) Fisher information은 log-likelihood function에 대해서 음수의 2차 미분을 한 것
**
https://velog.io/@veglog/Fisher-Information
# 정리 (2)



https://blog.naver.com/sw4r/221174111918
[수리통계학] Score function 란?
정의 (Score function): log-likelihood function의 1차 미분 값을 Score function이라고 부른다. 여기서...
blog.naver.com
https://blog.naver.com/sw4r/221112389275
[수리통계학] Fisher Information / Observed Fisher Information 정의!
피셔 정보와 관찰된 피셔 정보의 내용에 대해서 알아보자. 피셔 정보의 정의는 로그 가능도 함수에 대해서 ...
blog.naver.com
'AI > Data Science' 카테고리의 다른 글
| [Statistics] 기초통계학 정리 (0) | 2024.10.02 |
|---|---|
| 삼각 함수 공식 (1) | 2024.09.20 |
| [Statistics] 유의성검정, 검정통계량, F-분포, 분산분석 etc. (1) | 2024.09.19 |
| Symbols on prompt engineering (0) | 2024.07.26 |
| 프롬프팅 스킬 (0) | 2024.07.22 |