Reference(아주굿): https://sonsnotation.blogspot.com/2020/11/8-normalization.html
Normalization
1. 개념: 데이터의 범위를 사용자가 원하는 범위로 제한하는 것
2. 여러 기법
- feature들의 0~1 scale (ex. 이미지 데이터 픽셀이 0~255 사이의 값 → 0.0~1.0 사이의 값)
- 표준화(Standardization): 표준정규분포를 갖도록 평균을 빼고 표편으로 나누는 것
- whitening(e.g. batch normalization): 2단계로 구성 (1) Stardardize(standard normalize) pre-activation function (2) Scale and shift
etc.
3. 장점
: optimal solution으로의 수렴 속도가 빨라진다.
layer가 1개이든, 2개 이상의 딥러닝이든, 정규화를 할 경우 loss function의 형태가 elongated(타원형)에서 spherical(구 형)으로 바뀌고, optimal solution으로 가는 경로가 더 효율적으로 개선된다.

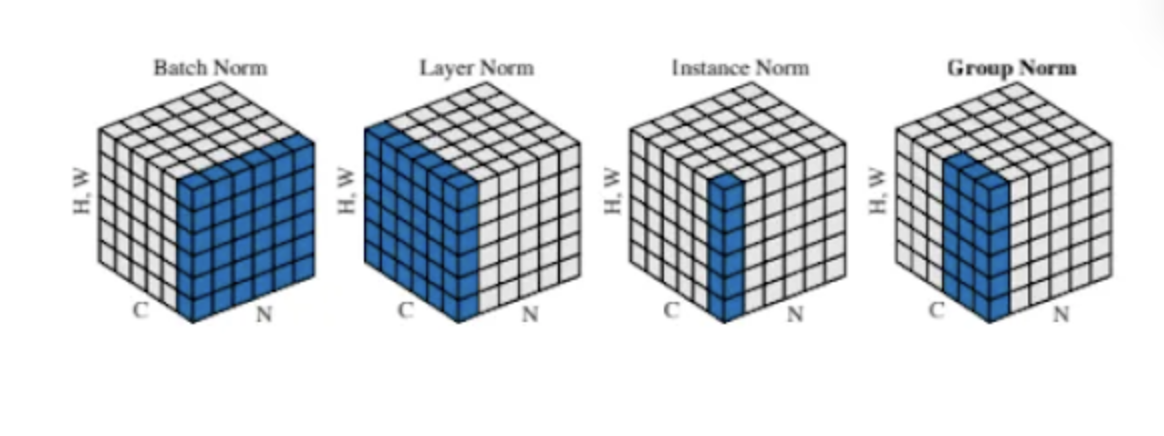
Batch Normalization & Layer Normalization

| Batch Norm | Layer Norm |
| - Whitening 기법 베이스 (0) 매 순간(=weight가 training되는 순간)마다 (1) Stardardize(standard normalize) pre-activation function (2) Scale and shift - 입력 데이터의 분포를 조정하여, 신경망 내부에서 학습 안정성과 속도 개선 |
|
| 주로 CNN, FCNN에서 활용 ->배치 내부의 통계적 변화로 인한 그래디언트 소실 문제를 완화 |
주로 RNN, 순차적 데이터(시퀀스) 다루는 경우 활용 -> 시간적인 의존성을 고려하여 안정적인 정규화를 제공 |
| 주로 mini-batch 내 데이터가 여러 개(=batch size가 2 이상)인 경우 -> 미니배치 크기에 영향을 받음 |
mini-batch에 들어있는 데이터가 한 개(=batch size가 1)인 경우에도 사용 가능 |
| Standardize에서 사용하는 평균과 표준편차는, mini-batch 내 모든 데이터의 Feature(채널) '별'로 평균과 표편을 계산. 테스트 시에는, 전체 데이터셋의 평균과 표편을 사용 (배치별로 구해뒀던 평균과 분산을 버리지 않고 메모리에 기억해뒀다가, 재사용) |
Standardize에서 사용하는 평균과 표준편차는, batch에 있는 '모든 feature(모든 채널)'에 대한 평균과 분산 즉, hidden layer 전체의 평균과 분산으로 normalization |
장점
layer가 여러 개인 DL에서 ...
- 기존에 back prop 시, activation function(eg. 기울기가 0인 영역이 넓은 sigmoid / tanh이나, G.V. issue를 간접적으로 회피하는 ReLU 등.)을 통과하면서 gradient vanishing 문제가 발생하는데,
매 순간 Whitening을 수행하여 input을 평균 0, 표준편차 1인 분포로 normalization시켜 주면,
- G.V. issue의 근본 원인인 Internal Covariance Shift 문제(아무리 input layer에서 정규분포를 가지는 입력을 줘도 hidden layer를 지나면서 그 분포가 점점 정규분포를 벗어나는 현상)를 해결


Whitening의 두 단계
1. Normalize pre-activation function : pre-activate 된 샘플을 standard normalize

2. Scale and shift : standard normalize 된 샘플의 variance와 bias를 조절할 수 있는 γ, β를 부과해서 parameterize

variance와 bias를 다시 조절하는 이유는 sigmoid의 경우는 중심에 분포가 몰려 있는 것이 효과적이지만, 다른 activation은 그렇지 않기 때문이다. 즉, 학습을 통해 γ와 β를 학습해 적절한 분포를 가지게 하기 위함.
'AI > Data Science' 카테고리의 다른 글
| [Metric Learning] Contrastive Learning, SimCLR, NCE (3) | 2023.08.28 |
|---|---|
| 폴더 내 파일 리스트/경로 리스트 생성 (0) | 2023.08.13 |
| [Tensorflow] Callback 콜백함수란? (0) | 2023.08.03 |
| Optimizer vs Learning-rate Scheduler (feat. 어떤 조합이 좋을까?) (0) | 2023.08.03 |
| ResNet50 (0) | 2023.07.30 |